3-3-1 データファイルの書式を定義する
データファイルのデータ構造を解析して、項目(フィールド)の名称と桁数を定義し、定義ファイルとして保存します。
この定義ファイルは、データと様式ファイルのフィールド情報をリンクさせるために使用されます。
動作設定の[ファイル書式定義]で設定を定義します。
CSVファイルの場合
ここでは、サンプルデータとして「Sample」ディレクトリにあらかじめ用意されている「sample_ja.csv」を使用します。
ブラウザーを起動し、APPLICATION MENU画面を表示します。
APPLICATION MENU画面
APPLICATION MENU画面で、Universal Connect/Xの[UCX 動作設定]をクリックします。
動作設定が起動します。初めて動作設定を起動したときは、サンプルとしてインストールされるデータファイルなどがすでに設定された状態で表示されます。
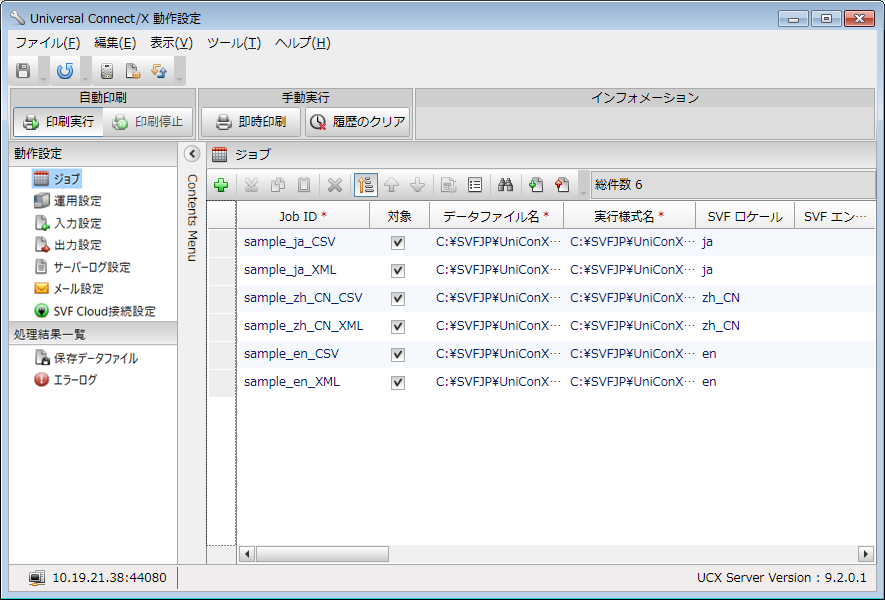
Universal Connect/X 動作設定
[ツール]-[ファイル書式定義]を選択するか、
 ボタンをクリックします。
ボタンをクリックします。[ファイル書式定義]画面が開きます。
Universal Connect/X 動作設定-[ファイル書式定義]
[ファイル]-[開く]を選択するか、
 ボタンをクリックします。
ボタンをクリックします。[ディレクトリ選択]画面が開きます。
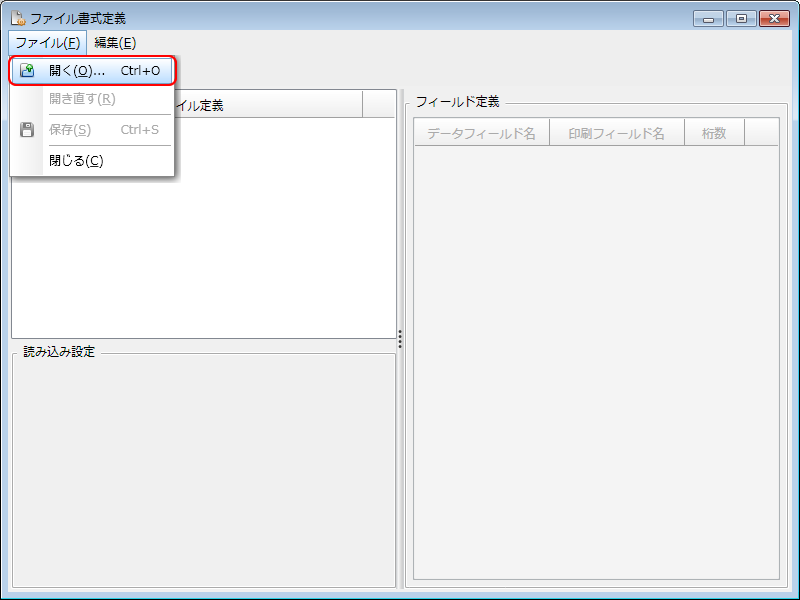
Universal Connect/X 動作設定-[ディレクトリ選択]
データディレクトリを選択します。
[参照パス]欄に直接入力するか、表示された項目からサンプルデータが入っているディレクトリを指定します。
 ボタンをクリックすると、[入力設定]の[データファイル]で指定されているデフォルトパスに移動します。
ボタンをクリックすると、[入力設定]の[データファイル]で指定されているデフォルトパスに移動します。
[ディレクトリ選択]画面
[OK]ボタンをクリックします。
[ディレクトリ選択]画面が閉じ、Universal Connect/X動作設定の[ファイル書式定義]に戻ります。
[ファイル定義]欄に表示された「sample_ja.csv」ファイルを選択します。
[読み込み設定]欄、および[フィールド定義]欄が表示されます。
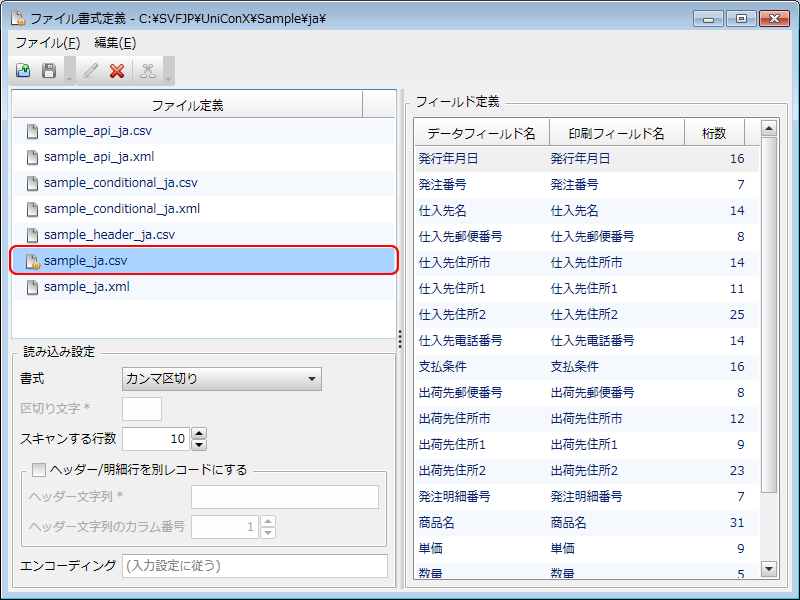
[ファイル定義]欄
サンプルデータの「sample_ja.csv」は、あらかじめファイル書式定義がされているため、[フィールド定義]欄には各項目とその値が表示されます。
ここでは、[フィールド定義]欄に[データフィールド名]や、[桁数]が設定されていることを確認します。
参考
ファイル書式定義がされていないデータファイルの場合は、[読み込み設定]の[書式]を設定したあと、[編集]-[フィールド定義の作成]を選択するか、
 ボタンをクリックしてフィールド定義を作成します。
ボタンをクリックしてフィールド定義を作成します。詳細は「4-5-1 ファイル書式定義の設定(CSV形式)」を参照してください。
フィールド定義が設定されていることを、確認したら画面を閉じます。
新規にファイル書式定義を設定する場合や、内容を変更した場合は、[ファイル]-[保存]を選択するか、
 ボタンをクリックして、設定を保存します。
ボタンをクリックして、設定を保存します。ファイル書式定義の内容がデータディレクトリ内のファイル書式定義ファイル(「schema.ini」)に保存されます。
参考
CSVデータファイルを使用する場合は、データファイルの書式を定義しなくてもよい場合があります。書式定義の設定が不要なケースについては、「4-3-1 [ジョブ]の操作と設定」の「ファイル定義」を参照してください。
ヘッダー明細別レコード形式 CSVファイルの場合
ここでは、「sample_header_ja.csv」というサンプルデータを利用します。
なお、ファイル書式定義をするファイルを指定するまでの手順は、「CSVファイルの場合」の手順1から手順6を参照してください。
[ファイル定義]欄に表示された「sample_header_ja.csv」ファイルを選択します。
[読み込み設定]欄が表示されます。
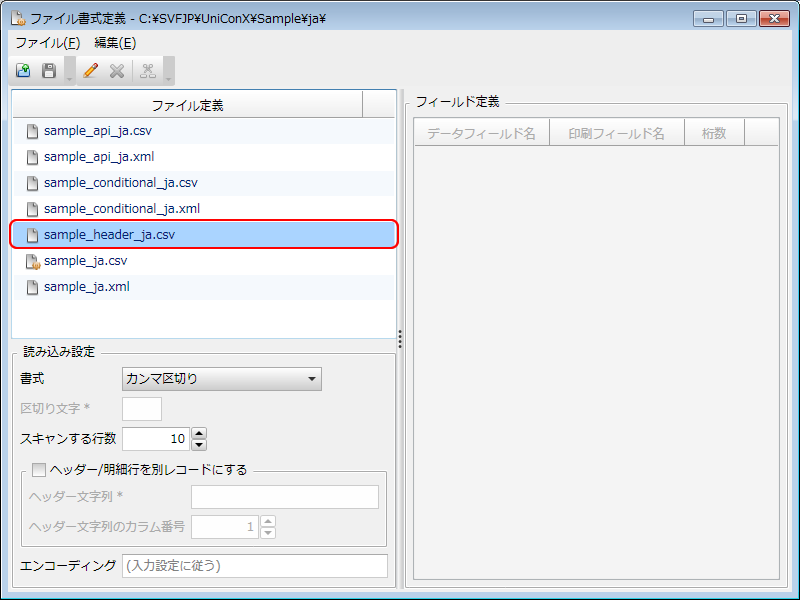
[ファイル書式定義]画面
データファイルの詳細設定をします。
[読み込み設定]欄でデータの区切り文字、形式を定義します。
「sample_header_ja.csv」はカンマ区切りデータなので、[書式]欄はカンマ区切りの指定のままにします。
このデータはヘッダー行、明細行が別になっています。[ヘッダー/明細行を別レコードにする]欄のチェックを付けます。
[ヘッダー文字列*]欄には、ヘッダー行と認識させるための文字列を入力します。
ここでは「*」と入力します。
[ヘッダー文字列のカラム番号]欄には、「ヘッダー文字列」が入ってくるCSVデータファイルのカラム番号を入力します。
ここでは「1」と入力します。
[エンコーディング]欄には、CSVデータファイルを読み込むときのエンコーディングを指定します。
ここでは「UTF-8」と入力します。
参考
CSVデータファイルを読み込むときのデフォルトのエンコーディングは、[入力設定]の[エンコーディング]で設定できます。詳細は「4-3-3 [入力設定]の操作と設定」を参照してください。
フィールド定義を作成します。
[編集]-[フィールド定義の作成]を選択するか、
ボタンをクリックします。データファイルの1行目の項目名が自動的に取り込まれます。また、「読み込み設定」欄で指定されている[スキャンする行数]が読み込まれ、各項目の最大バイト数が桁数として自動的に指定されます。
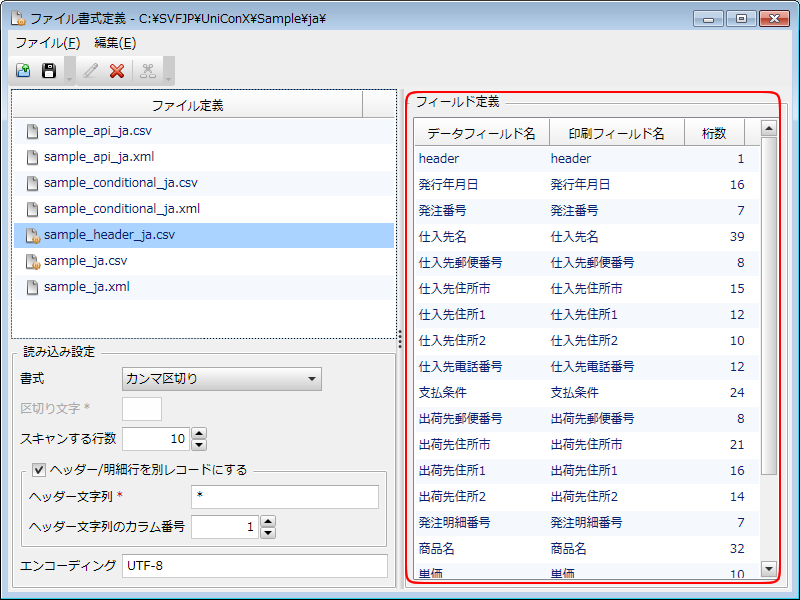
[フィールド定義の作成]
[ファイル]-[保存]を選択するか、
ボタンをクリックして、設定を保存します。ファイル書式定義の内容がデータディレクトリ内のファイル書式定義ファイル(「schema.ini」)に保存されます。
参考
CSVデータファイルを使用する場合は、データファイルの書式を定義しなくてもよい場合があります。書式定義の設定が不要なケースについては、「4-3-1 [ジョブ]の操作と設定」の「ファイル定義」を参照してください。
XMLファイルの場合
ここでは、「sample_ja.xml」というサンプルデータを利用します。
なお、ファイル書式定義を作成して、指定するまでの手順は、「CSVファイルの場合」の手順1から手順6を参照してください。
[ファイル定義]欄に表示された「sample_ja.xml」ファイルを選択します。
[読み込み設定]欄が表示されます。
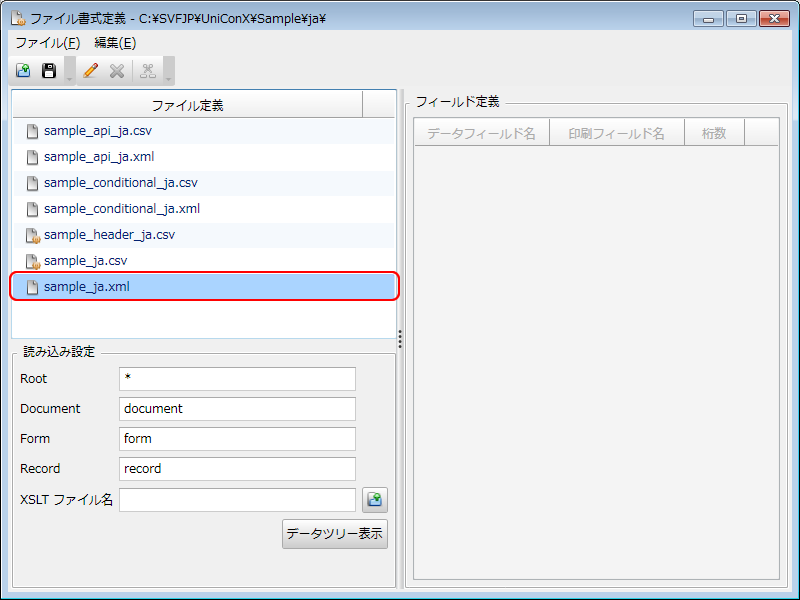
[ファイル書式定義]画面
[読み込み設定]欄でデータファイルの詳細を設定します。
[Root]、[Document]、[Form]、[Record]の各欄に、XMLデータファイル内で使用しているタグ名を入力します。ここではデフォルト定義のままにします。
参考
[データツリー表示]ボタンを押すと[データツリー表示]画面が別ウィンドウで開き、データ内で使用しているタグなどを参照できます。
フィールド定義を作成します。
[編集]-[フィールド定義の作成]を選択するか、
ボタンをクリックします。XMLデータ内のタグが自動的に取り込まれます。
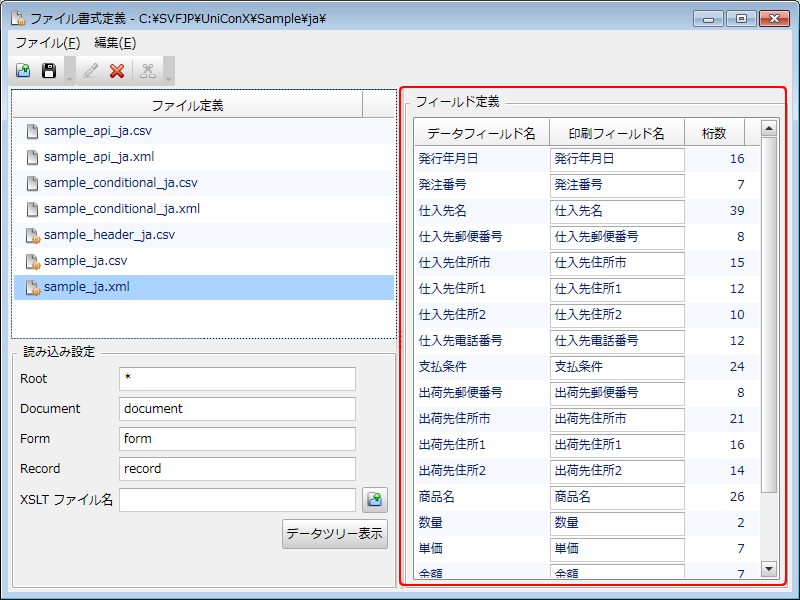
[ファイル書式定義]画面
[ファイル]-[保存]を選択するか、
ボタンをクリックして、設定を保存します。ファイル書式定義の内容がデータディレクトリ内のファイル書式定義ファイル(「schema.ini」)に保存されます。